Language Technology and Corpora-Corpus Linguistics
Welcome to this linguistics tutorial. On this site, you can learn some basic terms and applications in linguistics that I hope will help you with your langauge skills and possibly get you interested in Linguistics as a field of study and to see how it is applicable in the world.
Three areas of interest to me in Language Technology are: Digital Lexicography (digital dictionaries), language database and search engine development, and keywords and their associated phrases and their place in website commerce (as in search results in search engines and online business).
Language Technology and Corpora or Corpus Linguistics is a field which has really blossomed as computer technology has become more advanced and accessible. We can now gather, process, analyze, and learn from vast amounts of language data very easily and quickly. This screenshot demonstrates this concept. Here I did two searches, one using the term "faculty of philosophy" and the other "department of philosophy". As you can see by the locations of universities, the two terms can determine which results will appear. Website meta data can help Google determine sites it will detect. It is evident from this one example that European universities use the term "faculty" in a similar manner to how American universities use "department."
Which phrase a user enters will determine a lot of the results in a search. My primary interest in Language Tech/Corpus linguistics has been in making searches more efficient and linguistically broader or more inclusive. Consider if a European person is considering an American university to study philosophy. The hits using the European term won't do much good, but American universities can improve search results if they include European terms in the meta data in a website's programming. This meta data is used by search engines to produce more efficient results.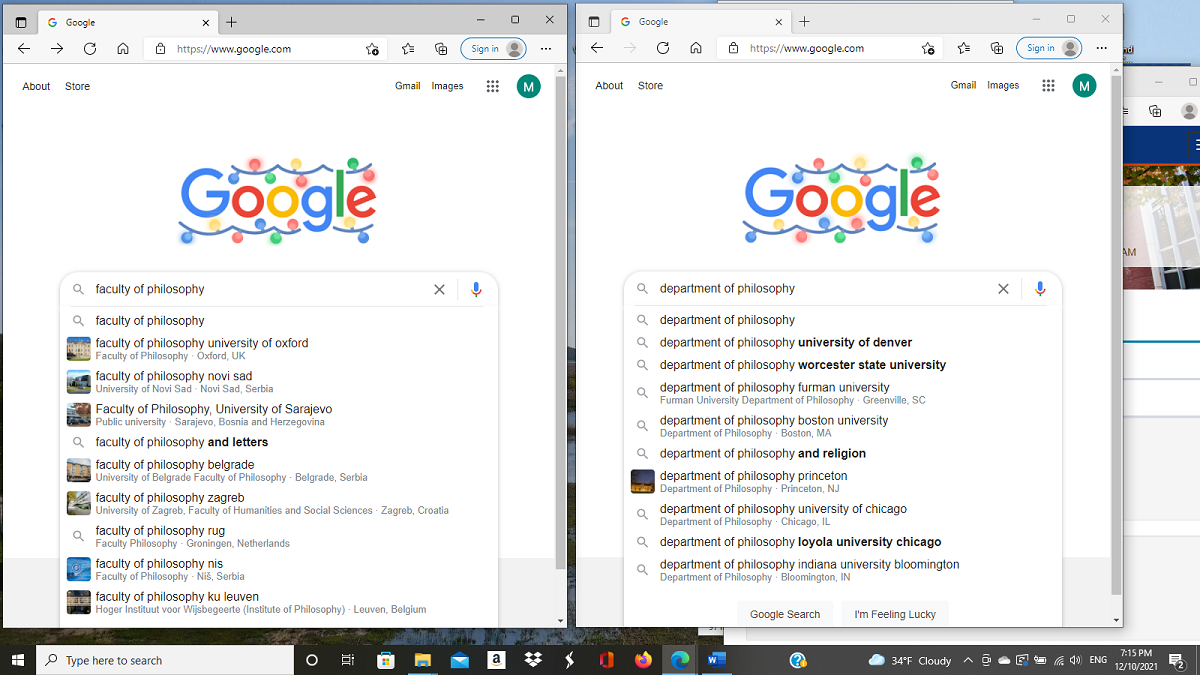
This is part of my presentation on keywords and phrases and how they are integrated into a website's meta-data. If you want to give your website specific meta-data that may help people searching find your site, you can add a meta-data section between the head tags. Just replace this university language with words and phrases specific to your website's subject matter.
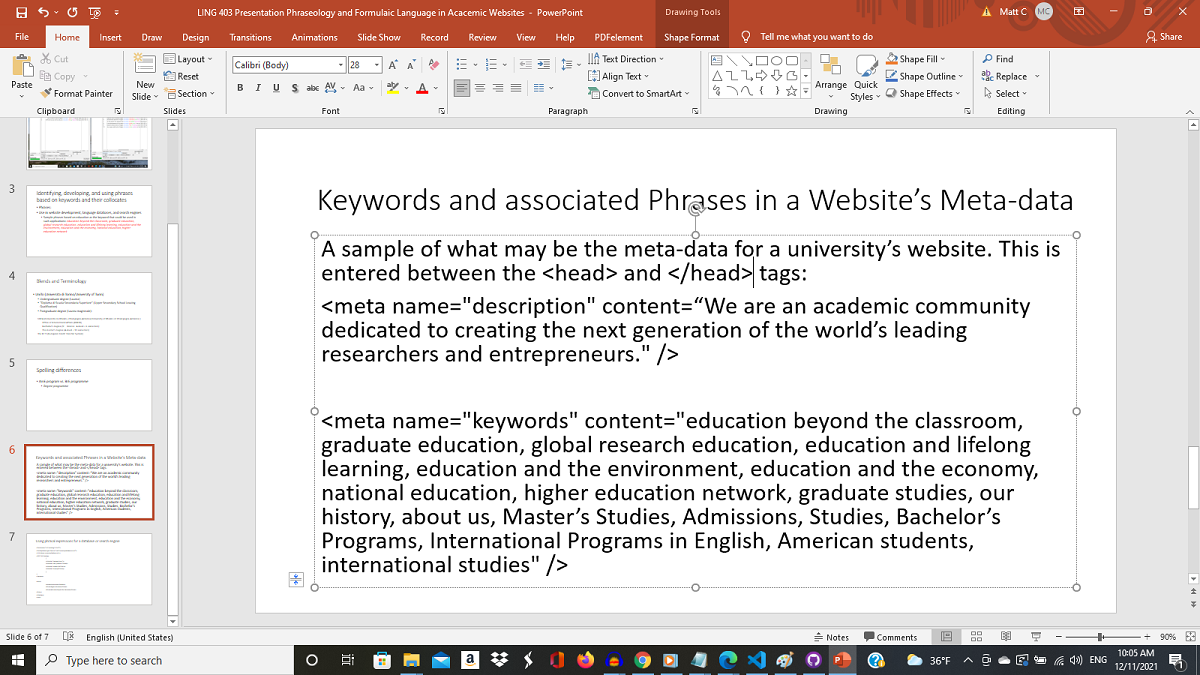
If you're having trouble deciding what terms or phrases are most frequent in your site's language, you can save all text in a file and run it through a processor that will rank words by frequency and show in a concordance other associated words to help you develop phrases that can be used in your website's meta-data. One such language processor is called AntConc; we have been using this in LING 403-Corpus Linguistics. For this project, I've used the Windows 64-bit (3.5.9) version. Another helpful resource can be a language corpus or "bank" which is continually updated and reveals language in use in a variety of contexts, showing how keywords and phrases are used and changing over time. There are several of these in many languages. The British National Corpus and the Corpus of Contemporary American English (COCA) can be helpful resources if your're working with English keywords and phraseology or formulaic sequencing.
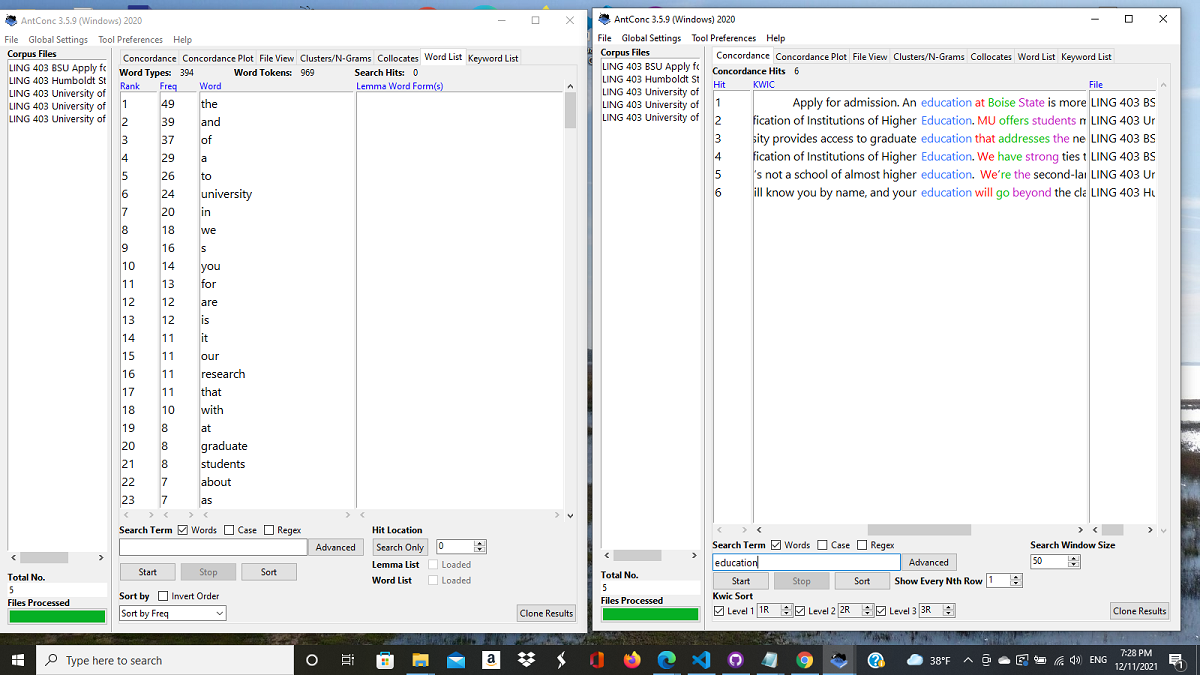
The following images can give you an idea how a program like AntConc works. In the first screenshot on the left is a word frequency count of the collection of language I gathered from American university web sites. Greater frequency is near the top. The second is how the word 'education' appears in relation to other words and what phrases it may trigger by using AntConc's concordance tool.
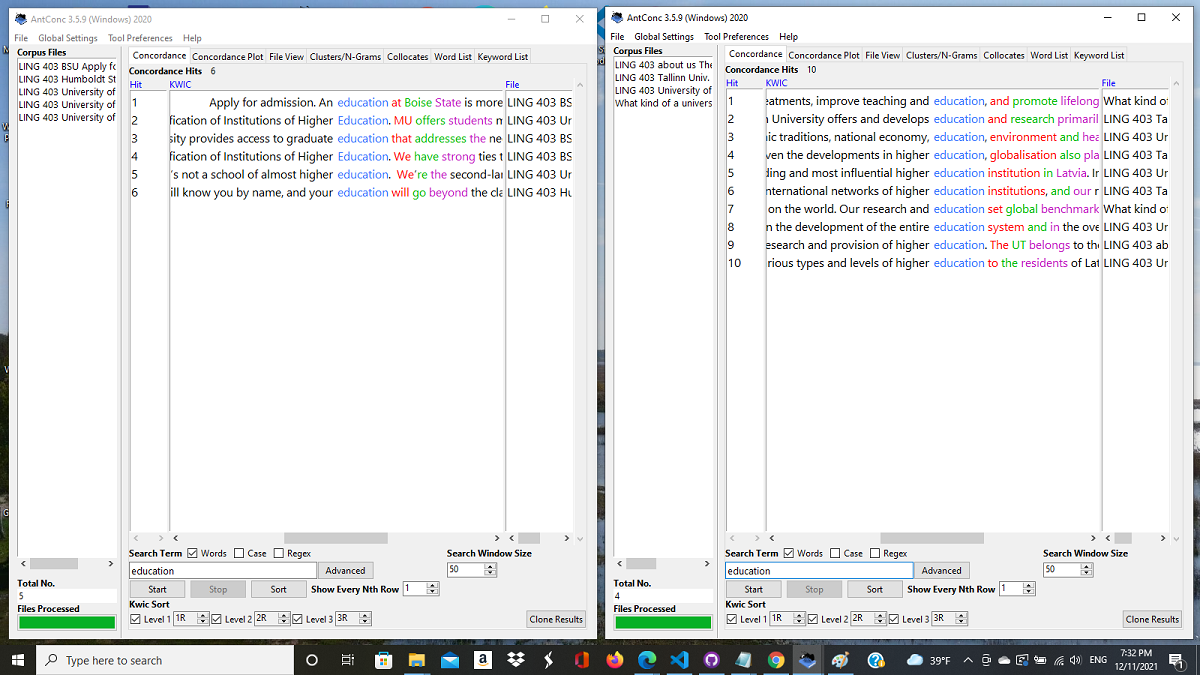
Different corpora can be compared. Here I have the American corpus concordanced on the left, the European corpus on the right. This reveals how the two "Englishes" use the word education and various phrases associated with the word.
Here are a couple of videos I made to show you the basics of using AntConc to generate a word frequency list and a concordance using a keyword (in this case education) with associated words or "collocates" as we call them.
Creating a word frequency list
Creating a concordance
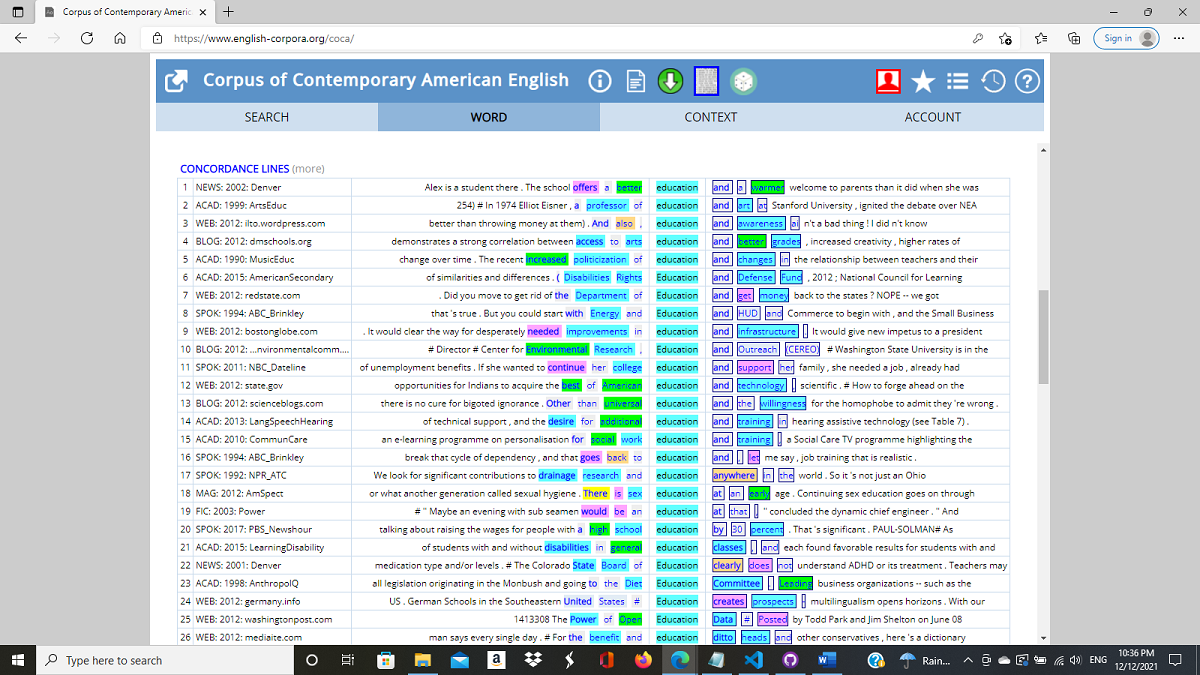
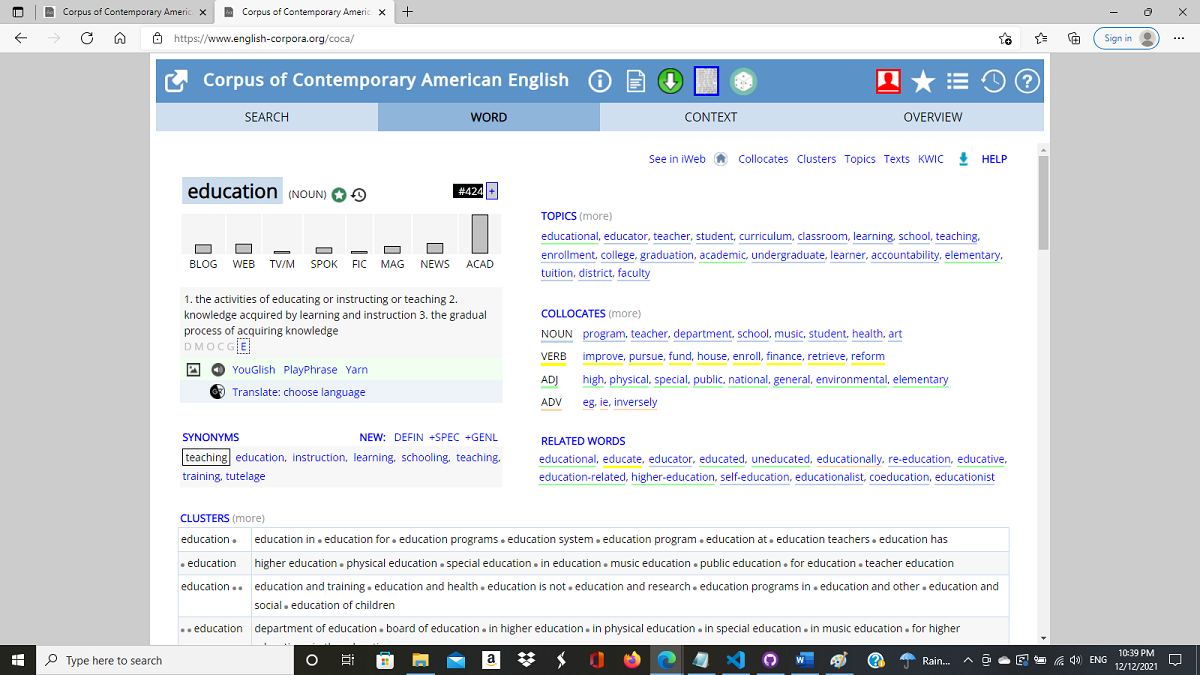
In the following couple of images, you can see how our keyword 'education' is analyzed in the COCA database. COCA contains millions of words collected from multiple sources. Academic articles are indicated with "ACAD" in the left column, "WEB" for the Web/Internet. It also shows in a graph the frequency of sources, in this ACAD is quite high.
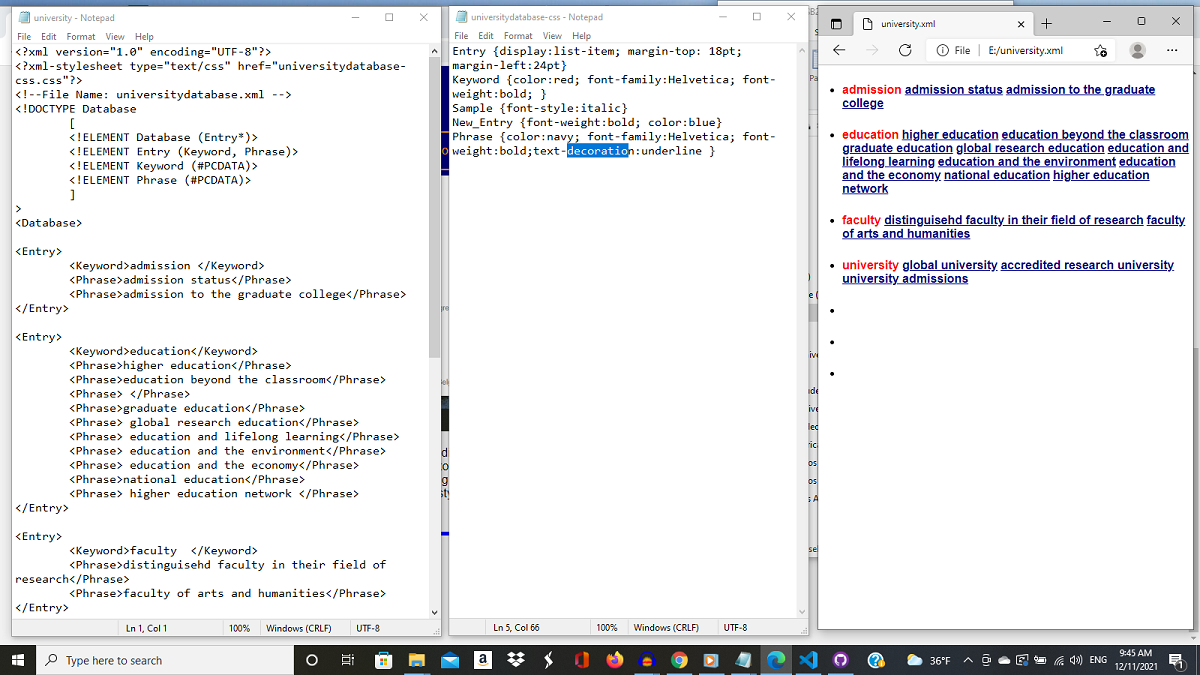
In the Lexicography course I focused on designing an online interactive dictionary that featured audio files and images. For this project, I had to familiarize myself with four coding languages: HTML, CSS, XML, and JavaScript. Dictionary compilation requires the development of a corpus of raw language data (collected words and phrases), a database, and a concordance to help analyze and organize information so it is presented accurately. This semester in Corpus Linguistics, I've used XML and CSS to construct a simple database of keywords and associated phrases. XML and CSS can be used to make simple databases. XML allows you to make your own tags that can be specific to the subject you are working with (for example, since I'm working with keywords and phrases, two tags I made are < Keyword > and < Phrase >). XML's syntax is similar to HTML, but an XML file has to have an associated stylesheet to display the data in a browser. I'll provide some screenshots and explanations of my work in this section....
The following image shows the XML file, associated style sheet, and browser view of keywords and phrases I have been developing in my research of academic keywords and phrases on university websites. Should I ever be working with adding meta data to a university website, I can refer to this database to help me come up with keywords and phrases appropriate to such a website.
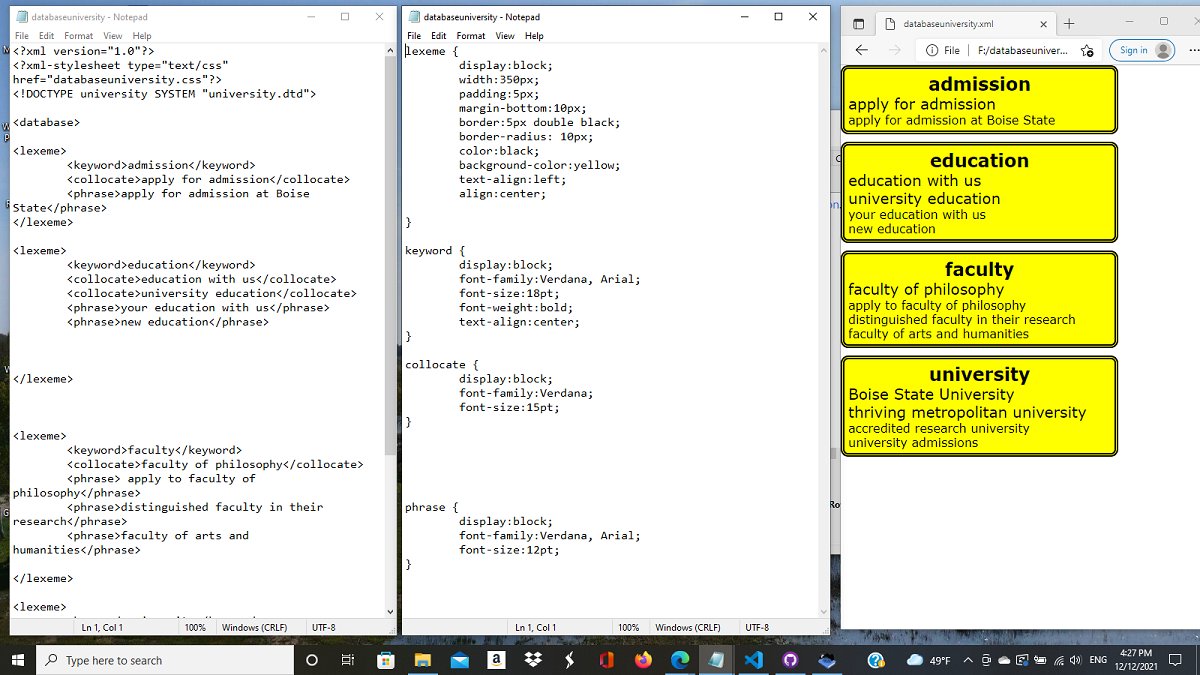
Here is a differenet scheme of a similar database, showing the XML file, associated stylesheet, and the output in a browser.
With additional HTML and JavaScript functions connected to the XML file, it's possible to extract information or words that can lead to another section of a website, to additional information, to an item, file, or other webpage:

These are just some of the ways Corpus Linguistics can be used. Besides internet commerce and dictionaries, language data can be collected and analyzed for variety of purposes, to see how languages or dialects change over time, to compare regional varieties of a language, to provide updates to language teaching and learning materials, to assist with editing and translation, and more.